The current release of Flatirons++, May 27 2025, does not require a license to train new PickX models. This means that Flatirons++ may be downloaded and installed on any number of machines and training run on all of them, freeing up licensed machines for other work.
Training data, whether from Flatirons or Phoenix, must have the following:
- A good set of first break picks covering all offsets. The picks don’t have to be perfect.
- Moveout trends defined. Again, these don’t have to be perfect. A bit of “wobble” in the curves may actually be beneficial.
Select type of training data
Start the Flatirons++ application launcher and select either “Train new model using Phoenix project data” or “Train new model using Flatirons project data”.
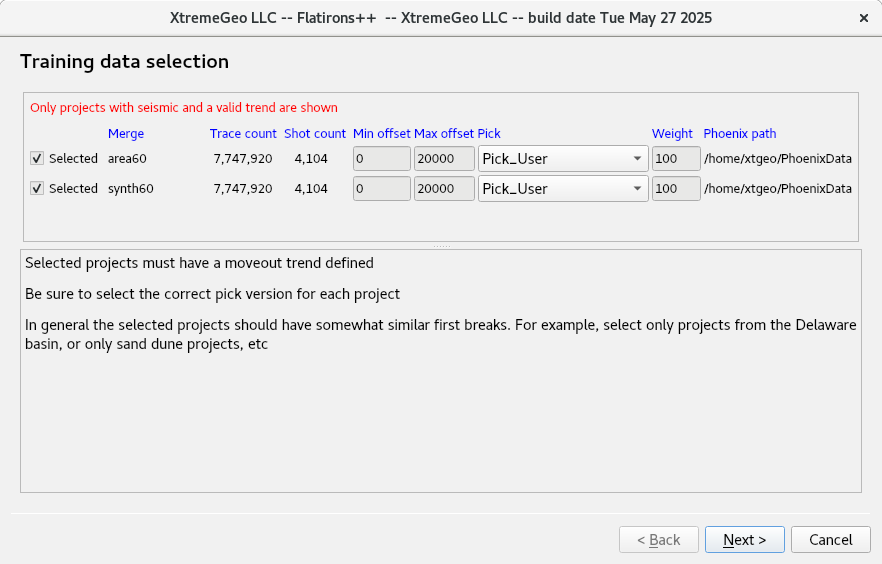
As a rule projects from the same general area should be selected, and if possible a mixture of projects with clean data and noisy data. For this example two synthetic projects have been selected:
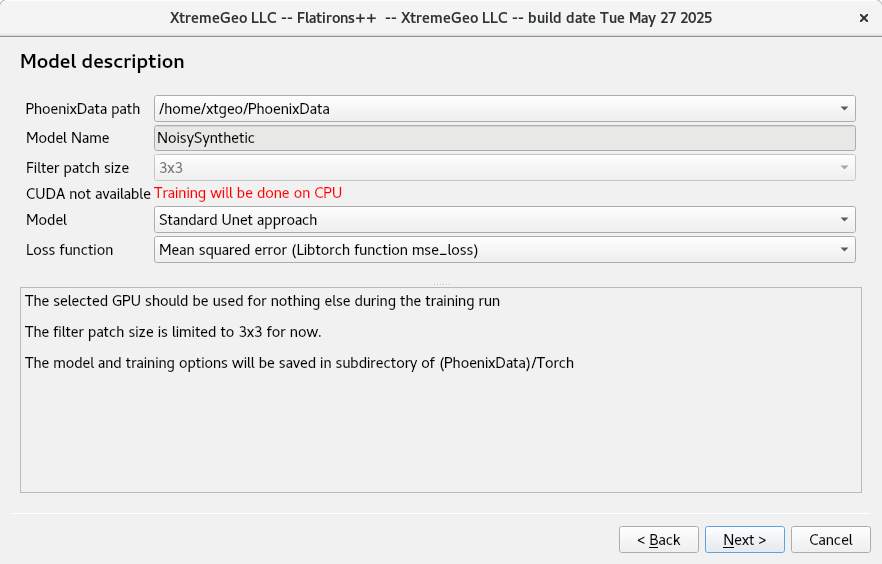
Model description page
On the next page of the wizard please select “Standard Unet approach” for the model and “Mean squared error” for the loss function.
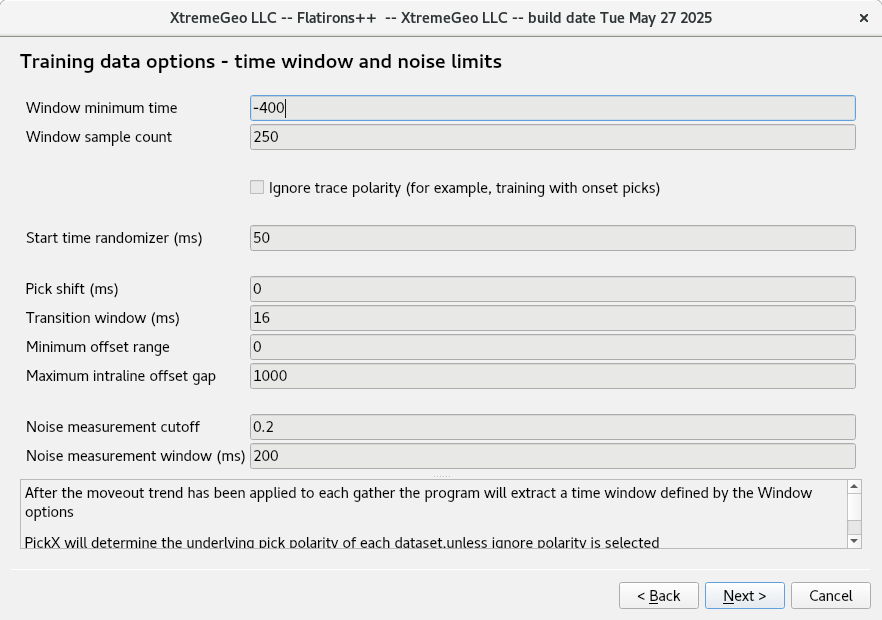
Training data options – time windows, noise limits
- Window options – after moveout has been applied a narrow (usually 800ms) time window is extracted from the gather. The defaults are usually fine
- Ignore trace polarity. Select this option if the training data was picked on amplitude onset
- Start time randomizer. This option stabilizes the model by adding some wobble to the trace start times after moveout has been applied.
- Noise measurement cutoff. This is a way of excluding picks on very noisy traces. A value of 1.0 is pure noise. The default value of 0.2 is probably too small for most surveys
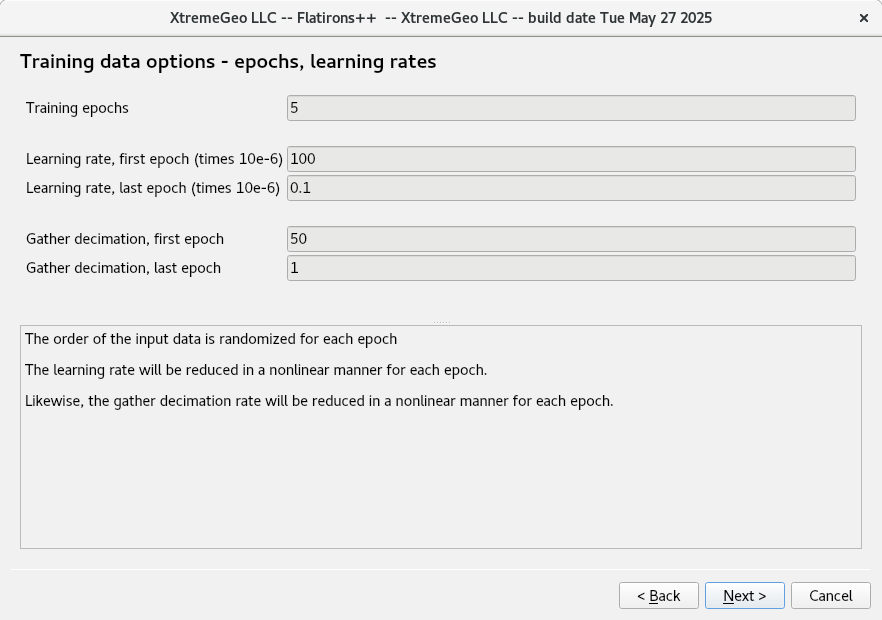
Training data options – Epochs and learning rates
- Training epochs. During each epoch the training rate is reduced and the number of gathers is increased.
- The default learning rates are fine
- Good values for the gather decimation rates depend on the number of gathers in all the selected surveys. If the selected surveys have more than a couple hundred thousand gathers then the decimations should be increased to something like 500 and 10.
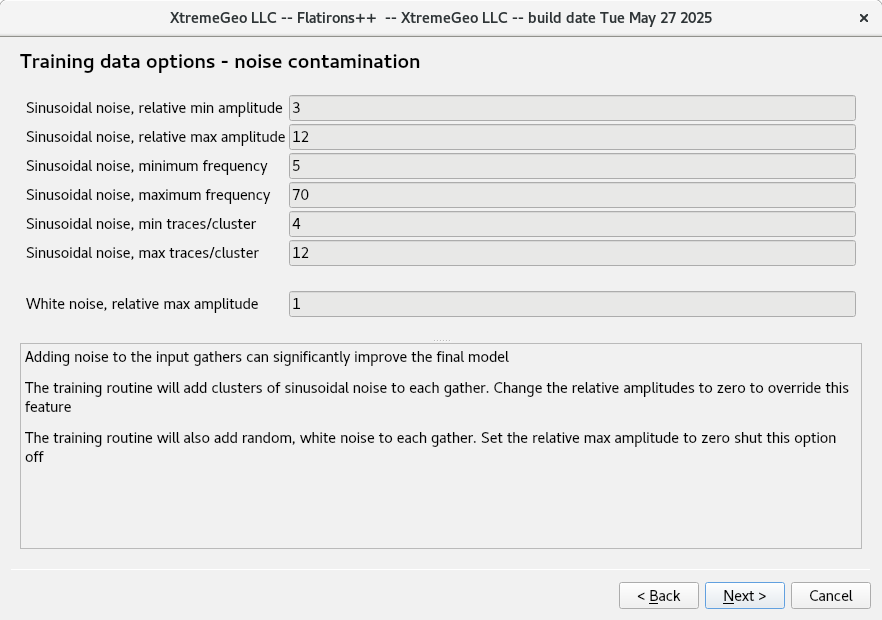
Training data options – noise contamination
These options are crucial to obtain a good model. The “sinusoidal noise” options mimic contamination from nearby shots. – Amplitudes – these should be decreased from the defaults to about 1.0 and 3.0 – The dominant frequency will be chosen at random for each gather – The number of traces on the sinusoidal cluster, chosen at random for each gather
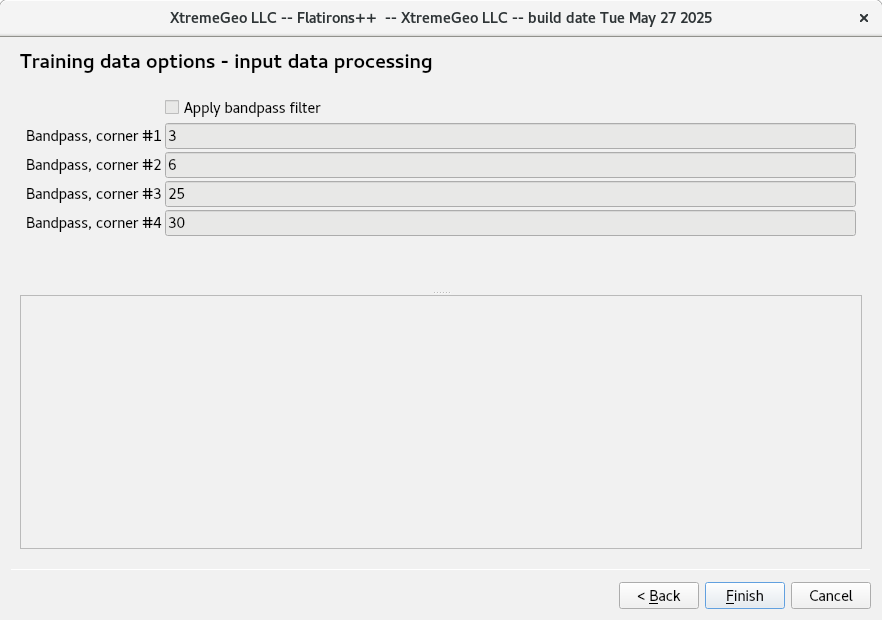
Training data option – input data filter
This option is rarely used, since in general noisy data can help stabilize the training.
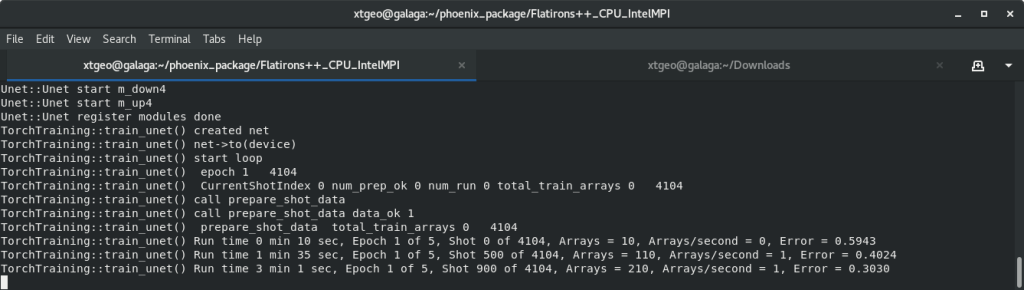
Start the training run and monitor training progress
Click “Finish”. On a CPU the training will take around 12 to 24 hours.
The progress of the training may be viewed in the terminal window used to launch Flatirons++. The print out will show epoch, shot within epoch, total arrays (gathers) using for training, and Error.
The Error should drop to roughly 0.02 fairly quickly and hover there. But don’t be fooled – much more training is required!
A decent machine should use about 4 arrays per second, and it takes a minimum of 50,000 gathers to obtain a good model.
NOTE – You don’t have to wait for training to finish to use the model. It is saved every few minutes and may be opened in other applications